Metadata Providers
A provider turns a series ID into canonical metadata. tsundoku's
resolution pipeline calls the active provider's resolve_by_foreign_id
and search methods to match incoming releases to series.
v1 ships only MangaBaka, but the architecture is provider-pluggable
via the
MetadataProvider
trait. Adding one means writing a td-metadata-<name> crate plus a
config block — no core changes.
/admin/providers is the
operator surface. Every registered provider shows up here; the
active one is marked, and each row surfaces offline-cache age, last
refresh status, and a Refresh cache trigger.
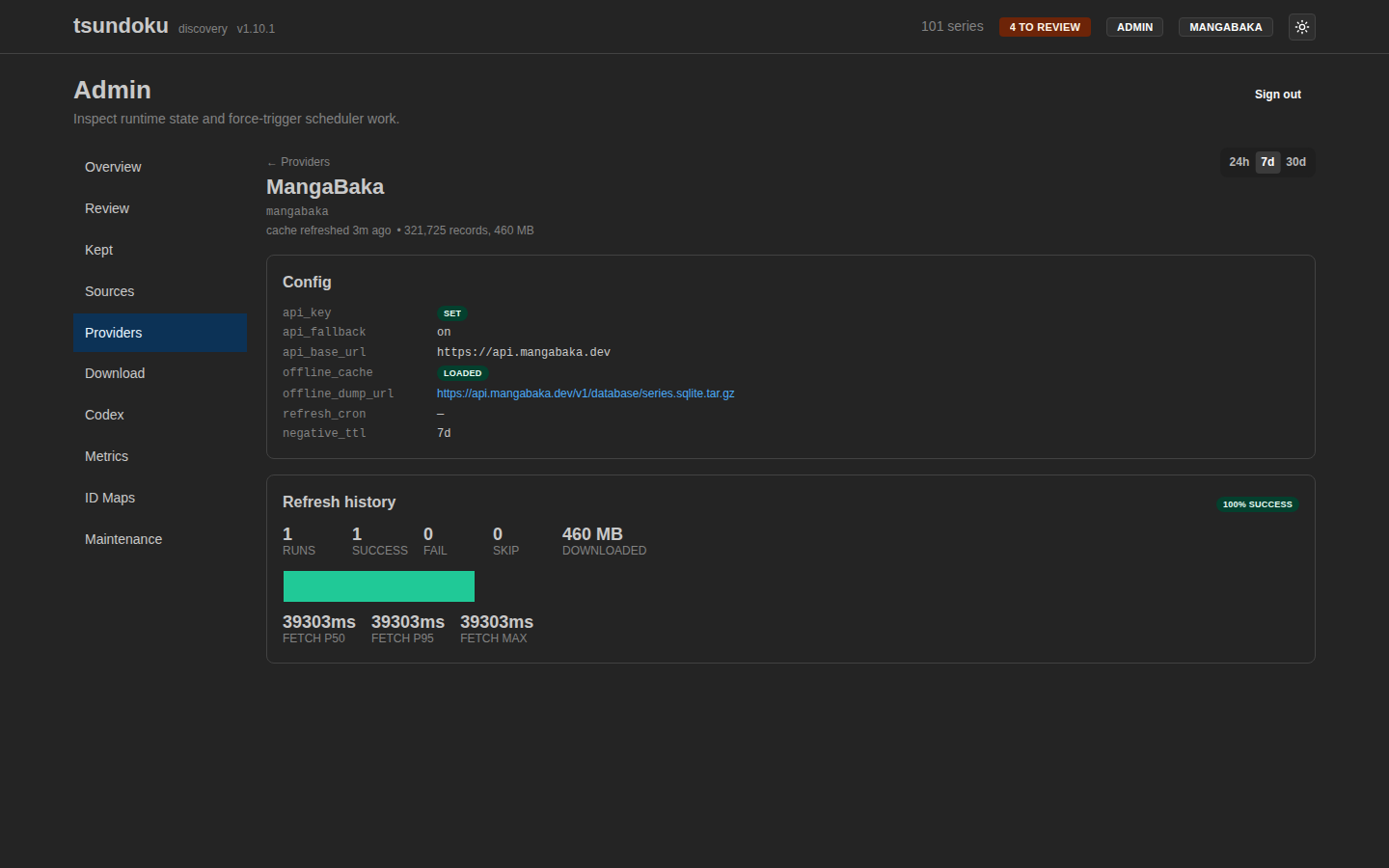
The per-provider detail page surfaces the offline dump's row count, the SHA-1 sidecar that gates re-extraction, and a recent-runs table.
Active vs. registered
Multiple providers can be registered (so the review UI can search
across them and the resolver can chain foreign-ID lookups), but exactly
one is designated metadata.active_provider and runs the
auto-resolution path. Switching is a config-level decision:
[metadata]
active_provider = "mangabaka"
MangaBaka
MangaBaka is the v1 active provider. The provider's design is
offline-first: a nightly SQLite dump is downloaded, opened
read-only as a side database, and queried via the bundled FTS5 mirror.
Live API calls only fire when explicitly enabled via api_fallback.
Offline dump lifecycle
MangaBaka publishes nightly dumps at
https://api.mangabaka.dev/v1/database/series.sqlite.tar.gz
(~476 MB compressed).
tsundoku refresh-provider-cache:
- Downloads the tarball + the SHA-1 sidecar.
- Verifies the hash.
- Extracts to
${data_dir}/cache/providers/mangabaka/series.sqlite. - Adds 8 source-id indexes + an FTS5 mirror for fast title search.
The extracted dump is opened read-only as a side database — queries run against MangaBaka's canonical rows directly. We don't re-ingest the 585k rows into provider-owned tables; drift would mean we're wrong, and the file is the source of truth.
Scheduled refresh
[providers.mangabaka]
offline_refresh_cron = "0 4 * * 0" # weekly Sunday 04:00 UTC
The scheduler will hit MangaBaka's dump endpoint at that cadence and swap the on-disk cache atomically when verification succeeds. A failure leaves the previous dump in place — the resolver keeps working against the stale version until the next successful refresh.
5-field crons are auto-padded to seconds-0.
api_fallback
[providers.mangabaka]
api_key = "mb-..."
api_fallback = true
When api_fallback = true and api_key is set, cache misses
trigger a live API call against api_base_url to fetch the canonical
record. Successful calls populate the in-memory cache so a repeat
within the same process is free; the next dump refresh picks up the
mapping permanently.
Without an api_key, the provider runs offline-only. Cache misses
surface as Ok(None) to the resolver and the release falls through
to fuzzy-title search.
Negative cache
negative_cache_ttl_days = 7 controls how long the provider remembers
"this foreign ID isn't in MangaBaka." Tombstone entries prevent
repeated API hits for IDs that genuinely don't exist. Adjust based on
how often you expect MangaBaka to backfill new entries.
Manual refresh
From the admin UI: Refresh cache on the MangaBaka card. The card's
in-flight pill shows live progress (Running... 47 / 200 (phase)) over
SSE and is hydrated from the latest provider_refreshes row on page
load, so it survives a hard refresh while a tick is still in flight.
From the CLI:
tsundoku refresh-provider-cache # all providers
tsundoku refresh-provider-cache --provider mangabaka # one specific provider
Both paths share the same JobLocks mutex with the cron job — manual
and scheduled refreshes can't race.
Series-row refresh
refresh-provider-cache swaps the provider's dump. It does not
touch any series row — the canonical title, description, cover URL,
genres, tags, volume / chapter counts, and rating stored on each
catalog row keep whatever values the resolver wrote when it first
matched the release.
Over time those rows drift from the provider's current state (MangaBaka backfills, the series advances, the description gets edited). The series-row refresh job walks the catalog and re-fetches each row's metadata from the active provider, persisting the result.
Config
[metadata.series_refresh]
cron = "0 5 * * *" # daily 05:00 UTC. Omit to disable the cron.
batch_size = 50 # max rows refreshed per tick. 0 = no-op (transient disable).
min_age_days = 7 # skip rows whose metadata is fresher than this.
min_age_days defaults to 7 to match MangaBaka's published-dump
cadence — refreshing a row whose metadata is one day old is wasted
work because the cache hasn't moved. Loosen or tighten based on the
upstream provider's churn.
5-field crons are auto-padded to seconds-0, like every other cron in tsundoku.
Triggers
| Path | Use |
|---|---|
Scheduled cron (metadata.series_refresh.cron) | Hands-off; runs continuously while serve is up. |
POST /api/v1/series/refresh-all | Kick a batch now, from the admin UI or curl. Returns 202 with { triggered, skipped, batchSize, minAgeDays, provider }. |
tsundoku refresh-series | Same code path; for cron-from-outside or one-shot batches when serve isn't running. Accepts --batch-size / --min-age-days overrides. |
POST /api/v1/series/{id}/refresh-metadata | Refresh a single series row by id — bypasses min_age_days, runs synchronously. Used by the admin UI's per-series action. |
All bulk paths share the same provider-scoped job lock as
refresh-provider-cache: a manual trigger that lands while a refresh
is already in flight returns triggered: false, skipped: true rather
than starting a second batch.
A series with no mapping for the active provider is skipped silently
on the bulk path; the single-id endpoint returns 409 Conflict so
the operator knows the row needs a manual link first.
Forcing a rewrite when the hash matches
Each provider-backed series row carries a metadata_hash. If the
incoming canonical payload hashes to the same value as the stored row,
the refresh short-circuits and the row isn't rewritten. That's the
right default — until a denormalized column gets added to the series
table. Existing rows then show the old shape (e.g. NULL for a newly
added volumes column) and the hash match keeps them that way
forever.
POST /api/v1/series/invalidate-metadata-hashes is the escape hatch:
it clears every hash so the next refresh tick rewrites the row from
scratch. Manual rows are always left alone. The response is
{ invalidated, skippedManual }. Pair it with the Refresh all
series metadata trigger above to actually rewrite the rows; the
clear by itself is cheap and changes nothing observable.
Exposed in the UI as a card on the admin Maintenance page.
Metrics
Every refresh attempt writes a row to provider_refreshes. Surfaced
on the admin metrics tab:
- Bytes downloaded per refresh.
- Record count after extraction.
- P50 / P95 dump-download latency (just the HTTP portion, separate from extract + indexing time).
- Error-kind donut on failures, same enum as
poll_runs.
Adding a new provider
Implement the
MetadataProvider
trait in a new td-metadata-<name> crate, add a [providers.<name>]
config block, and add one line to the registry builder. If the
provider has an offline dump, ship a nested sea-orm migrator inside
the provider crate; the top-level migration::Migrator composes it.
No core changes.