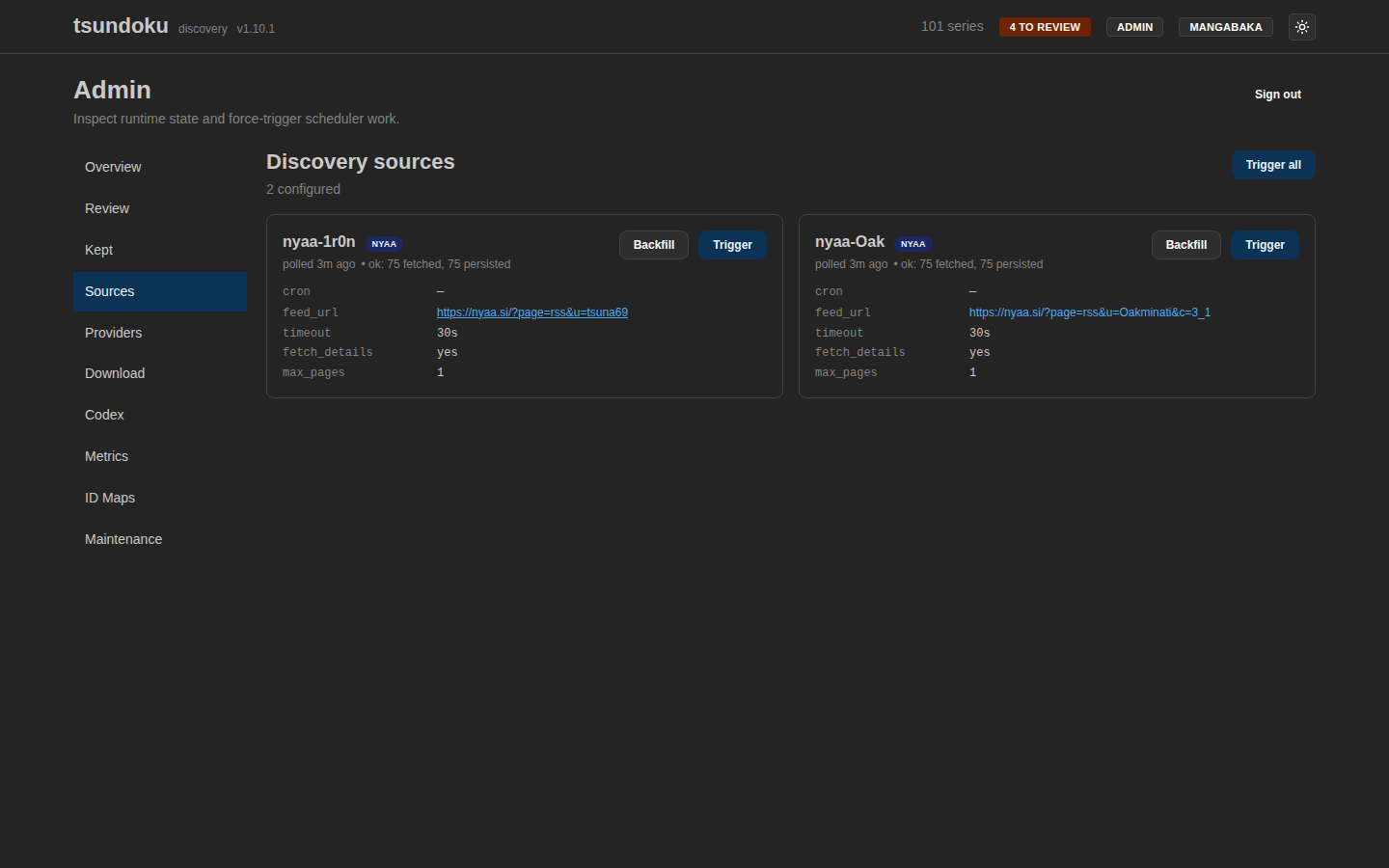
Sources
A source is a polled discovery feed. Each [[sources]] config
block produces one instance. v1 ships only the Nyaa source, but the
architecture is source-pluggable via the
DiscoverySource
trait — adding a new source means writing a td-source-<name> crate
and adding a config kind, no core changes.
The admin shell at /admin/sources
lists every registered source with its last poll time, last summary,
and a Poll now button that shares its job lock with the cron tick.
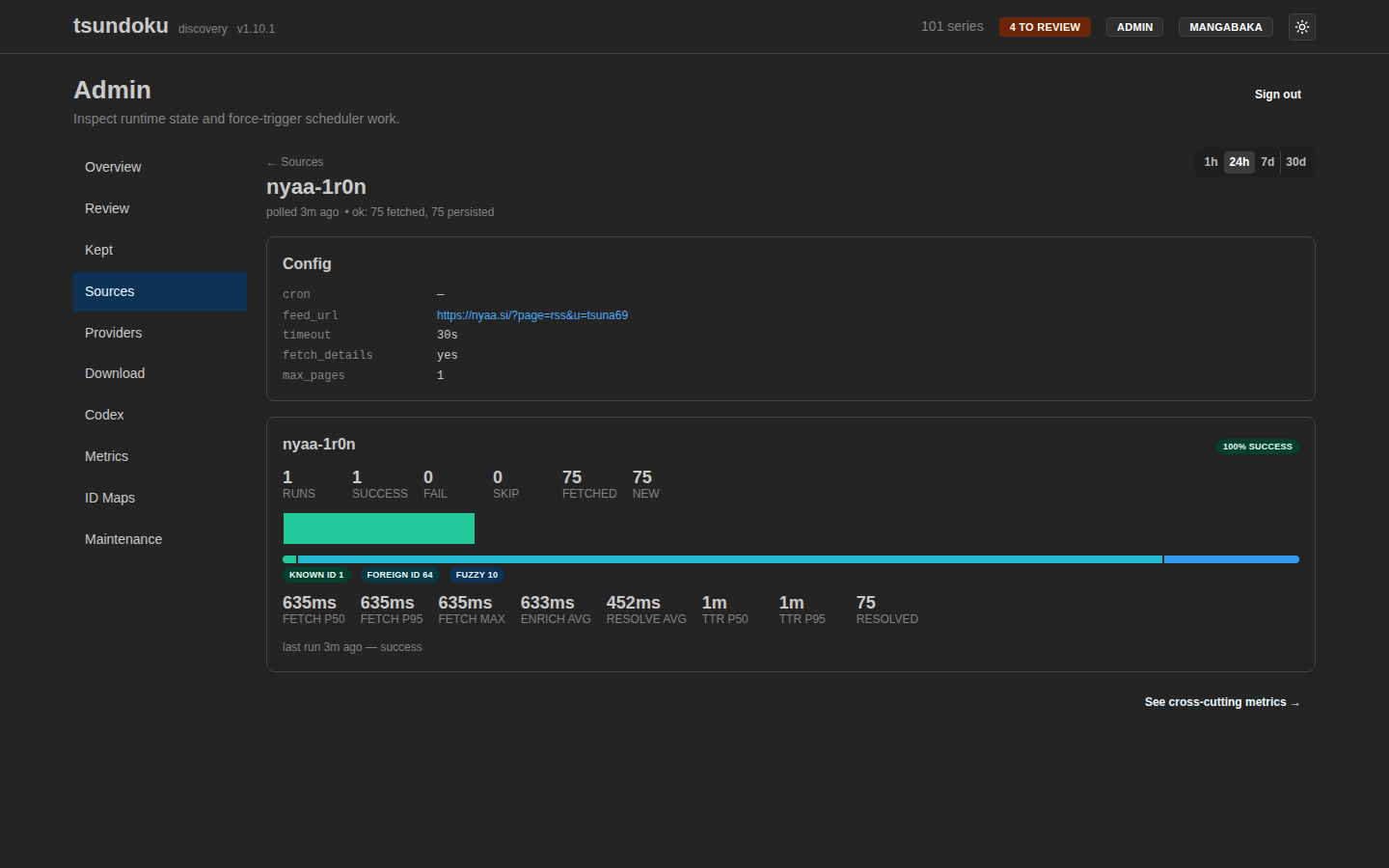
Drilling into a row shows the per-source detail page with recent runs, the full effective config, and historical metrics.
Nyaa
The Nyaa source polls an RSS feed and (when fetch_details = true,
the default) fetches each post's HTML detail page to enrich the file
list and extract external provider links (MangaUpdates, AniList, MAL,
MangaDex). Those links flow into the resolver's foreign-ID lookup
step.
Feed URLs
The Nyaa search box generates RSS-compatible URLs. Useful filters:
| Query param | Purpose |
|---|---|
c=3_1 | Literature → English-translated |
c=3_2 | Literature → Untranslated |
c=3_3 | Literature → Raw |
f=2 | Trusted uploaders only |
q=<term> | Search query |
u=<uploader> | Filter by uploader name |
Example: trusted English-translated manga from a specific uploader:
https://nyaa.si/?page=rss&c=3_1&f=2&u=1r0n
You can register multiple [[sources]] blocks pointing at different
queries — one per uploader, one per language, one per cron cadence —
without changing anything else.
fetch_details: true (default)
When on, the source fetches each post's HTML detail page after parsing the RSS feed. This extracts:
- The torrent's file list (used by the format detector to tag the
release as
cbz,epub, etc.). - External provider links in the description (MangaUpdates, AniList, MAL, MangaDex). These feed the resolver's foreign-ID step and short-circuit fuzzy-title search entirely when a match exists.
Trade-off: one extra HTTP request per release. At Nyaa's typical
release cadence this is comfortably under any rate limit. Set to
false only if you're polling unusually fast or against a proxied
feed where the detail-page URL pattern doesn't apply.
MangaUpdates legacy ID handling
Nyaa uploaders often paste pre-2022 MangaUpdates URLs like
series.html?id=151349. Those numeric IDs no longer resolve directly
against MangaBaka (which indexes the modern alphanumeric form,
e.g. 6z1uqw7). The resolver handles this transparently:
- Extract the legacy URL → tag it
mangaupdates-legacy. - Check the
mangaupdates_id_mapSQLite cache. - On cache miss: issue one throttled
HEADrequest to the legacy URL, read MangaUpdates' permanent-redirectLocationheader, persist the mapping (or a tombstone if the legacy ID is dead). - Feed the modern ID into the existing foreign-ID lookup path.
Per-host throttle is one request per second with exponential backoff
on 429. The cache builds organically from real traffic — no
upfront seeding required.
Scheduling
Each source's cron field controls its schedule. Five-field
expressions are auto-padded to seconds-0:
cron = "0 */2 * * *" # every 2 hours
cron = "*/15 * * * *" # every 15 minutes
cron = "0 0 4 * * *" # 04:00:00 daily (six-field)
Omit cron to disable the scheduled poll for that source — the
tsundoku poll --source <name> one-shot still works for ad-hoc runs.
Concurrency: per-source mutexes prevent overlapping ticks. If a
previous tick is still running when the next cron fires, the new tick
is dropped with a debug-level log. The same locks gate manual
triggers from the admin UI — a manual POST /sources/{name}/poll
returns { triggered: false, skipped: true } when work is already in
flight.
Manual operations
From the admin UI (/admin):
- Trigger — poll a single source on demand.
- Trigger all — fan out across every registered source. Returns
per-source
{ triggered, skipped }so partial-in-flight states are visible.
Each source row shows an in-flight pill while a poll is running. The
pill is driven by the GET /api/v1/events/jobs SSE stream, falls back
to the inFlight snapshot on SourceDto after a hard refresh, and
renders Running... 47 / 200 once the poll loop publishes its first
progress checkpoint.
From the CLI:
tsundoku poll # all sources
tsundoku poll --source english-manga-trusted
Backfill (historical catch-up)
A poll only sees the current feed. To walk a source's older listing
pages and resolve everything it finds, use backfill. It is idempotent on
(source_kind, external_id) — re-running with the same --pages re-fetches
nothing already stored — and never moves the source's ETag / last_polled_at
markers.
Two ways to run it, and the difference matters when serve is up:
Endpoint (preferred while serve runs). Runs in-process under the
same per-source mutex the cron poll holds, so it cannot race a scheduled
tick:
curl -X POST -H "Authorization: Bearer $ADMIN_TOKEN" \
"http://localhost:8080/api/v1/sources/english-manga-trusted/backfill?pages=10"
Returns 202 with { triggered, skipped, pages }. skipped: true means a
poll or backfill for that source was already in flight (no-op). Sources whose
kind can't backfill return 422. The walk itself runs in the background;
watch progress in the logs or the admin UI's job events.
CLI (offline / one-shot). Builds its own connection and runs the same loop:
tsundoku backfill english-manga-trusted --pages 10
serve is usingThe CLI is a separate process, so its per-source lock does not
coordinate with a running serve. Two processes resolving the same
source at once is wasteful (duplicate fetches) and, on a filesystem where
SQLite's WAL is unreliable (notably Docker Desktop macOS bind mounts),
risks database disk image is malformed corruption. Keep the database on
a named volume (the default in docker-compose.yml), and while serve
is running, prefer the backfill endpoint over docker compose exec … tsundoku backfill. Use the CLI when serve is stopped, or for a DB on a
real native filesystem.
Metrics
Every poll tick writes a row to poll_runs (cron + manual triggers
both). Surfaced on the admin metrics tab:
- Success rate per source over a configurable window.
- Resolution-outcome stacked bar: known-id / foreign-id / fuzzy / review / failed.
- Error-kind donut for failures:
network,http_status,parse,db,internal. - P50 / P95 fetch latency per source (just the outbound HTTP portion, separate from total tick time).
See Review queue for what to do with releases that don't auto-resolve.
Adding a new source
Implement the
DiscoverySource
trait in a new td-source-<name> crate, add a [[sources]] kind = "<name>" config schema variant, and register it in the source
registry builder. No core changes. The PRD's "Future Considerations"
section in the local plans has the full step list.